Chat settings
Open chat settings
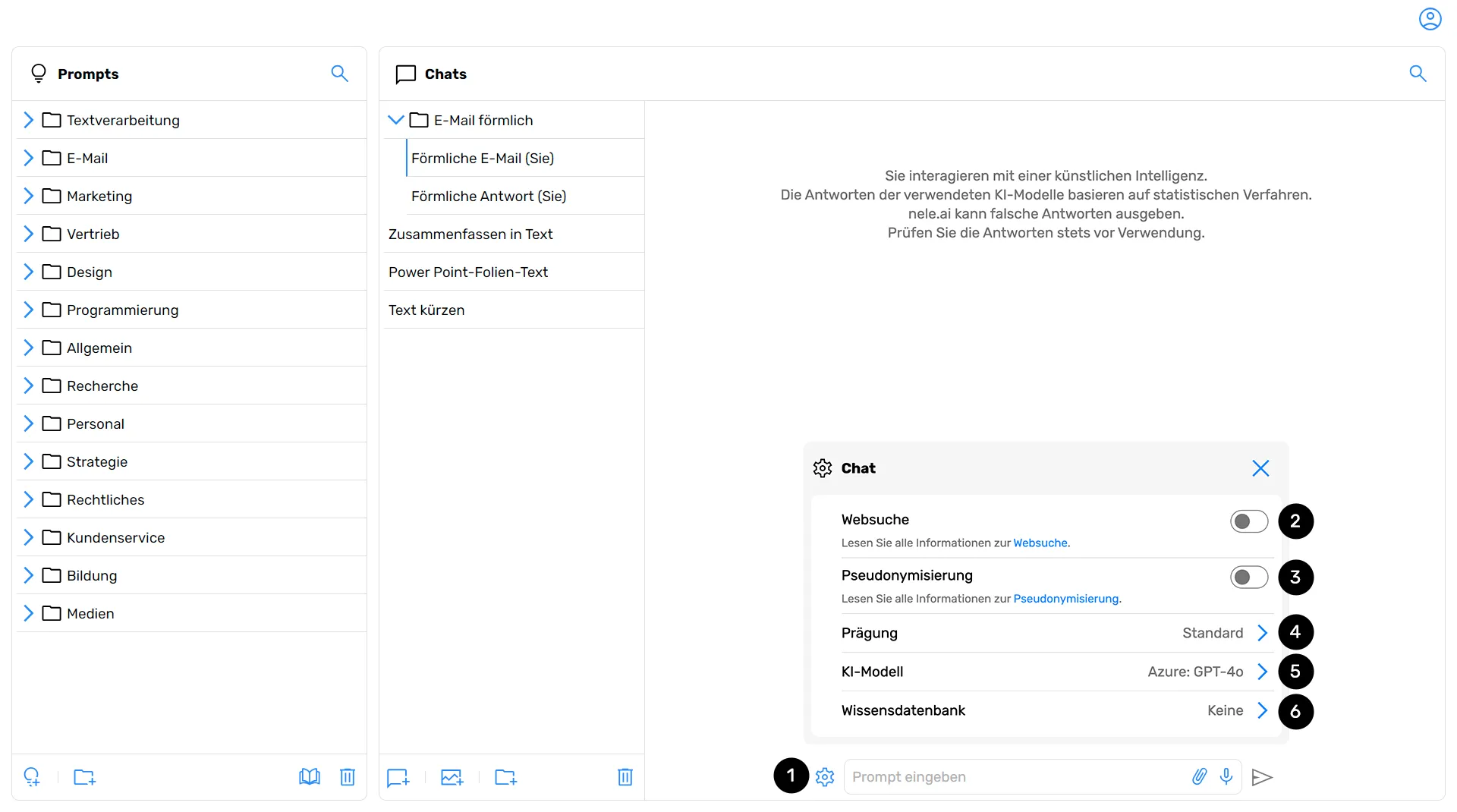
While chatting with nele.ai, you can adjust various settings. Click on the gear icon at the bottom left of the chat window (1) to open chat settings.
Here are the options for web search (2), pseudonymization (3), embossing (4), the AI model selection (5), the reasoning setting and the knowledge databases (6), provided that knowledge databases are activated for you.
Websearch
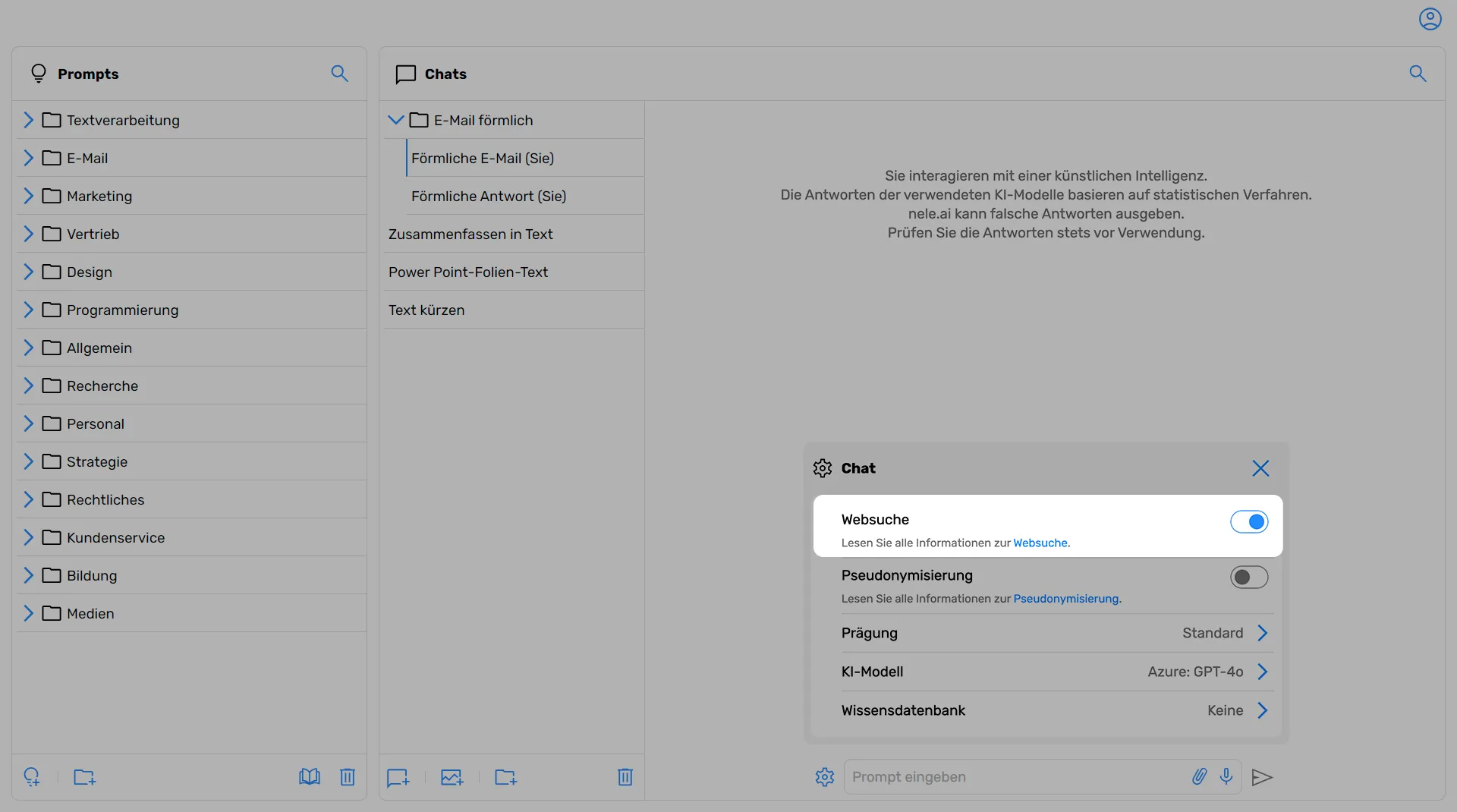
The web search function enables nele.ai to retrieve current information from the internet and incorporate it into responses. This feature must be authorized by your administrator before it can be used.
How web search works
When you have activated web search and enter a prompt, search terms are automatically generated from it and sent once to an AI-powered search engine. The search results are then compiled by the currently active AI model into a comprehensive response. Both sources and up to 5 links to external websites are displayed in the answer.
Country setting for web search
When using web search for the first time, you can select the country from which the search query should be sent to specify the results. This setting influences the relevance and regional focus of the search results. The selected country can be adjusted at any time later in the chat settings.
Activating web search
Web search can be turned on and off via a control element. If the function is not visible in your chat settings, it has not yet been authorized for you by your administrator.
Pseudonymization of personal data
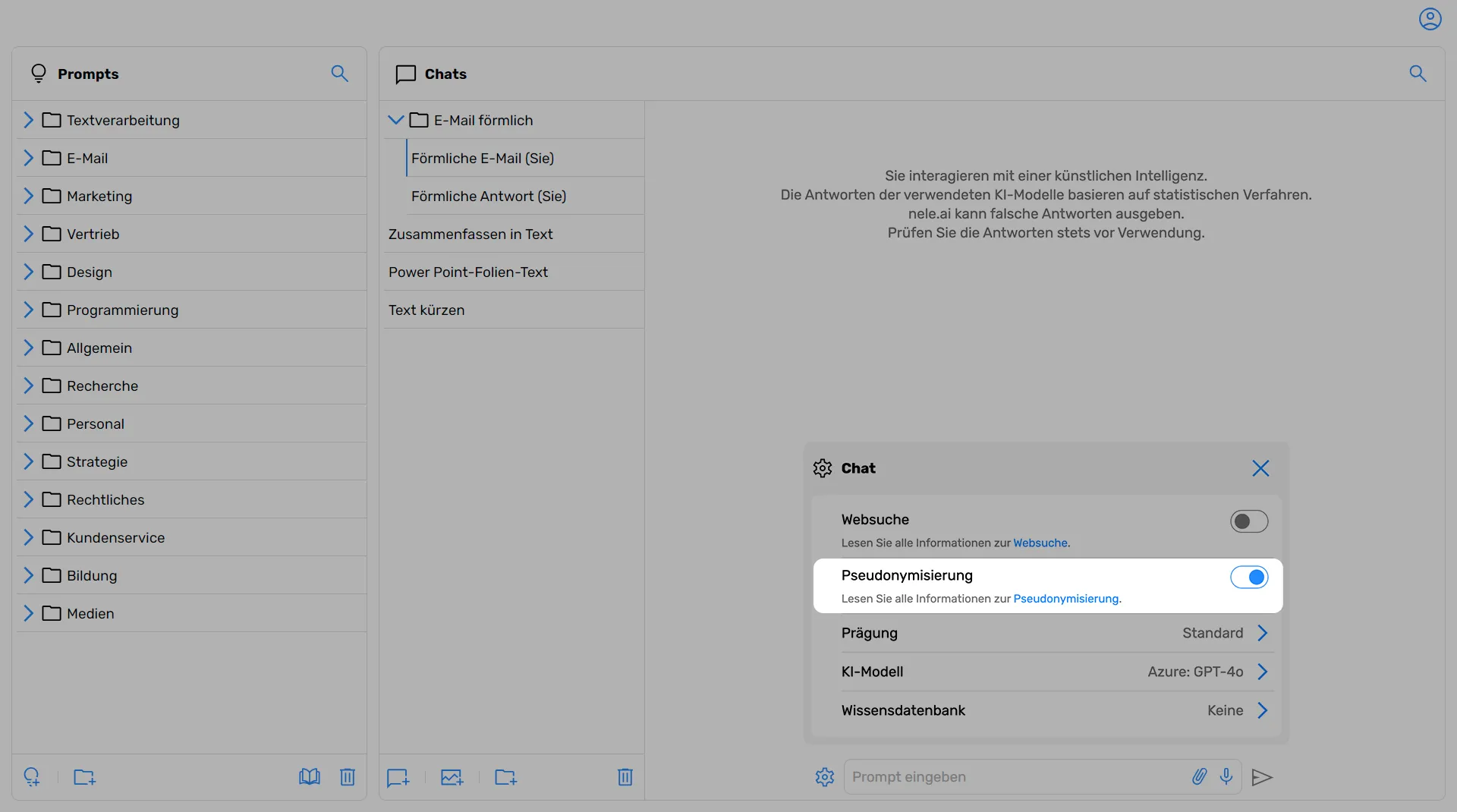
Pseudonymization can be turned on and off via a control element.
What is pseudonymization?
In pseudonymization, personal data is processed in such a way that it can no longer be directly attributed to a specific person without additional information. The pseudonymization feature of nele.ai provides additional protection for personal data that you use when making requests to the AI model.
This data is pseudonymized
This feature replaces, where technically detectable, personal information such as email addresses, IBANs, credit card information, ID numbers, license plates, and IP addresses as well as full names before transmission and reinserts them after receiving the message. Pseudonymization is performed through pattern recognition using regular expressions, name databases, and natural language processing.
Enabling and disabling pseudonymization
Pseudonymization can be enabled and disabled at any time. It may be necessary to turn off the function when you are searching for information about a public figure and need real data, such as their name, to conduct proper research. The feature can also be used in conjunction with web search, but may affect the quality of the query in this case.
nele.ai remains privacy-compliant even with the filter disabled
Pseudonymization serves to increase the level of data protection and has no impact on the security of your data. Regardless of the function's status, your information is stored exclusively on nele.ai servers and is never used for training AI models.
Feature description
The pseudonymization feature is optional and provides additional data security. It should be noted that the results do not depend on using this pseudonymization feature. Privacy compliance is maintained even when the pseudonymization feature is not used. The following explains and describes how the pseudonymization feature works:
When needed, unique personal information in user queries can be replaced with anonymous placeholders before transmission. This affects first and last names, phone numbers, email addresses, IBAN numbers, credit card data, ID numbers, vehicle registration numbers, IP addresses. Administrators can globally enable pseudonymization in the admin backend as the default setting for all new chat conversations of their team. Users also have the option to set pseudonymization as the default for their new chat conversations in the application settings. The feature can also be turned on or off directly in new and active chats, with this individual setting overriding the global ones.
The pseudonymization process includes a local preliminary check of chat requests in text form (graphical text representation is not included) for sensitive content before they are forwarded to the AI models. The identification of sensitive data is performed through a regular expressions procedure (RegEx procedure), where user requests are compared with various predefined patterns as well as a database of currently 11,000 first and last names. Matching content is replaced with numbered placeholders like [[lastname_placeholder_001]]. This method allows AI models to correctly interpret the texts without having to access specific personal information. The numbering of placeholders ensures precise later retranslation. The breakdown of used placeholders and original content The pseudonymized messages are then sent to the AI models for processing. After receiving responses, they are checked for assigned placeholders and locally replaced with the original information. During streaming of AI responses, users see the texts including placeholders and can thus follow the process. It may happen that personal data is not recognized. This can occur when all characters of an input do not exactly match one of the stored patterns or when a name is not contained in the database. Such cases can be triggered, for example, by unexpected spellings with spaces or special characters. Anomalies in pseudonymization can be reported via a contact form. This enables adjustment of patterns and name databases. To strengthen transparency and trust in the pseudonymization process, users can see the texts including placeholders during streaming of AI responses. This allows them to verify the correct application of pseudonymization.
Testing the reliability of pseudonymization
Based on tests conducted by the data controller, the pseudonymization feature achieves an effectiveness rate of 98.43%. This means that in 98.43% of cases, pseudonymization was performed correctly by reliably replacing all sensitive data with placeholders, meeting data protection requirements. Taking into account all tested cases, including those where too much was pseudonymized, the overall success rate is 95.29%. This additional consideration includes cases where the pseudonymization feature still showed certain irregularities in the exchange or assignment of placeholders.
Embossing

An imprint allows you to customize the AI personality of nele.ai and tailor it to your needs. The AI takes on a role assigned by you, from which it then acts.
With such embossing, you can automate repetitive tasks, for example. This would include: “You translate every text you enter into English according to (...) the following rules. Your answers consist only of the translation, without any additional information.” Another example of embossing is: “You are a psychologist and check the mood of the entered text. You only answer “positive,” “neutral,” or “negative.” You don't give a reason and only answer with that one word.”
In the text box (1) You can customize an imprint by entering your own instructions for the AI personality If you make an adjustment, it is automatically adopted. You can also save this embossing as a standard embossing (2). If you have saved the default embossing, it will be applied to current and all new chats using nele.ai. You can change the embossing at any time in the settings of a chat. You can also use the standard embossing in the Program settings view.
AI model

You can choose from various language models that define the behavior and capabilities of AI. Choose the right model depending on the application, e.g. for programming, creative writing, etc..
Choose the right AI model
To work effectively, you only need two different AI models - a strong model such as OpenAI gPT4-o or Claude 3 Opus, and a weak model such as GPT 3.5 Tubo or Claude 3 Haiku.
You always use the strong model when your prompts involve complex relationships, for example when there are many dependencies or conditions. On the other hand, if you work with clear, simple instructions, you can choose a weak model. The advantage of these weak models is that they require significantly fewer credits for the same amount of words.
Reasoning
With selected AI models, you have the option to adjust the intensity of the reasoning process. Reasoning is the ability of the AI model to think through complex problems step by step before generating a final answer.
What is reasoning?
In reasoning, the AI model analyses your request in several thought steps and weighs up various solutions before reaching a conclusion. This leads to more precise and well-thought-out results, particularly when it comes to complex logical, mathematical or analytical tasks.
Set reasoning levels
For models with configurable reasoning, you can choose between different intensity levels. The available options are shown as a drop-down menu in the chat settings:
- Standard configuration: The model works with little or no reasoning effort. This setting is in line with traditional response behavior and is pre-selected by default when opening a new chat with a reasoning model. It is suitable for simple inquiries and maintains the usual response speed.
- Low: A reduced reasoning effort for tasks with slight complexity.
- Medium: A balanced reasoning effort for moderating complex issues.
- High: An intensive reasoning process for particularly demanding, complex or logically branched problems.
For some models, the reasoning intensity is fixed by the provider and cannot be adjusted manually. In these cases, only the default configuration is shown.
When should reasoning be used?
Reasoning is particularly helpful for:
- Complex logical conclusions
- Mathematical calculations and analyses
- Multi-level problem solving
- Tasks that require a structured approach
For simple inquiries such as short text summaries, translations or information requests, the standard configuration is usually sufficient.
Knowledge databases

Under “Knowledge Base”, you can select which data sources the AI Assistant should use for its answers. This allows you to control the information base on which AI builds its answers.
For example, you can use company-specific documents or websites that were previously provided by your company by an administrator. In this way, you get more accurate and relevant results for your inquiries.
If you don't see the Knowledge Base field, this feature isn't included in your functionality.
Please also read our articles on the subject knowledge databases and the Difference between knowledge bases and chat context. Administrators create knowledge bases in admin area.